Feedback Recurrent Autoencoder for Video Compression
Adam Golinski (University of Oxford)*, Reza Pourreza (Qualcomm), Yang Yang (Qualcomm Inc.), Guillaume Sautiere (Qualcomm AI Research), Taco S. Cohen (Qualcomm)
Keywords: Generative models for computer vision
Abstract:
Recent advances in deep generative modeling have enabled efficient modeling of high dimensional data distributions and opened up a new horizon for solving data compression problems. Specifically, autoencoder based learned image or video compression solutions are emerging as strong competitors to traditional approaches. In this work, We propose a new network architecture, based on common and well studied components, for learned video compression operating in low latency mode. Our method yields competitive MS-SSIM/rate performance on the high-resolution UVG dataset, among both learned video compression approaches and classical video compression methods (H.265 and H.264) in the rate range of interest for streaming applications. Additionally, we provide an analysis of existing approaches through the lens of their underlying probabilistic graphical models.Finally, we point out issues with temporal consistency and color shift observed in empirical evaluation, and suggest directions forward to alleviate those.
SlidesLive
Similar Papers
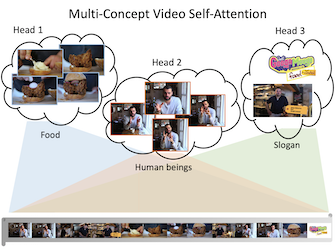
Transforming Multi-Concept Attention into Video Summarization
Yen-Ting Liu (National Taiwan University)*, Yu-Jhe Li (Carnegie Mellon University), Yu-Chiang Frank Wang (National Taiwan University)
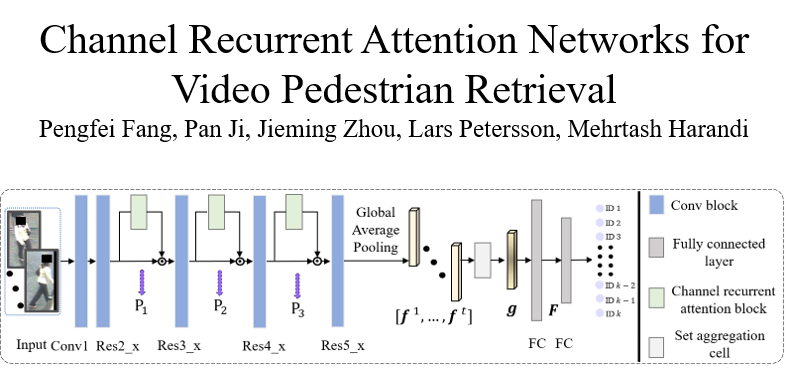
Channel Recurrent Attention Networks for Video Pedestrian Retrieval
Pengfei Fang (The Australian National University)*, Pan Ji (OPPO US Research Center), Jieming Zhou (The Australian National University), Lars Petersson (Data61/CSIRO), Mehrtash Harandi (Monash University)
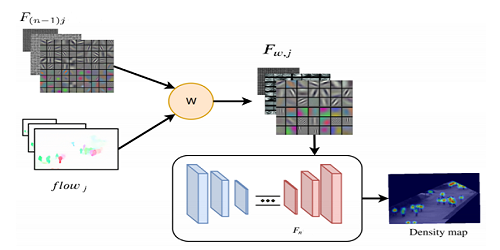
Video-Based Crowd Counting Using a Multi-Scale Optical Flow Pyramid Network
Mohammad Asiful Hossain (HUAWEI Technologies Co, LTD.)*, Kevin Cannons (Huawei Technologies Canada Co., Ltd ), Daesik Jang (Personal Research), Fabio Cuzzolin (Oxford Brookes University), Zhan Xu (Huawei Canada)