Channel Recurrent Attention Networks for Video Pedestrian Retrieval
Pengfei Fang (The Australian National University)*, Pan Ji (OPPO US Research Center), Jieming Zhou (The Australian National University), Lars Petersson (Data61/CSIRO), Mehrtash Harandi (Monash University)
Keywords: Applications of Computer Vision, Vision for X
Abstract:
Full attention, which generates an attention value per element of the input feature maps, has been successfully demonstrated to be beneficial in visual tasks. In this work, we propose a fully attentional network, termed channel recurrent attention network, for the task of video pedestrian retrieval. The main attention unit, channel recurrent attention, identifies attention maps at the frame level by jointly leveraging spatial and channel patterns via a recurrent neural network. This channel recurrent attention is designed to build a global receptive field by recurrently receiving and learning the spatial vectors. Then, a set aggregation cell is employed to generate a compact video representation. Empirical experimental results demonstrate the superior performance of the proposed deep network, outperforming current state-of-the-art results across standard video person retrieval benchmarks, and a thorough ablation study shows the effectiveness of the proposed units.
SlidesLive
Similar Papers
Video-Based Crowd Counting Using a Multi-Scale Optical Flow Pyramid Network
Mohammad Asiful Hossain (HUAWEI Technologies Co, LTD.)*, Kevin Cannons (Huawei Technologies Canada Co., Ltd ), Daesik Jang (Personal Research), Fabio Cuzzolin (Oxford Brookes University), Zhan Xu (Huawei Canada)
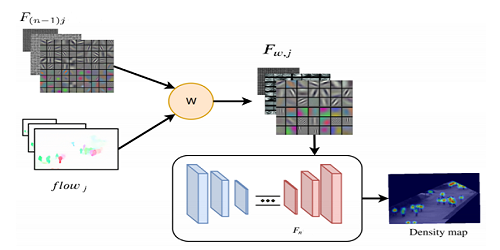
Transforming Multi-Concept Attention into Video Summarization
Yen-Ting Liu (National Taiwan University)*, Yu-Jhe Li (Carnegie Mellon University), Yu-Chiang Frank Wang (National Taiwan University)
Feedback Recurrent Autoencoder for Video Compression
Adam Golinski (University of Oxford)*, Reza Pourreza (Qualcomm), Yang Yang (Qualcomm Inc.), Guillaume Sautiere (Qualcomm AI Research), Taco S. Cohen (Qualcomm)