Transforming Multi-Concept Attention into Video Summarization
Yen-Ting Liu (National Taiwan University)*, Yu-Jhe Li (Carnegie Mellon University), Yu-Chiang Frank Wang (National Taiwan University)
Keywords: Video Analysis and Event Recognition
Abstract:
Video summarization is among challenging tasks in computer vision, which aims at identifying highlight frames or shots over a lengthy video input. In this paper, we propose an novel attention-based framework for video summarization with complex video data. Unlike previous works which only apply attention mechanism on the correspondence between frames, our multi-concept video self-attention (MC-VSA) model is presented to identify informative regions across temporal and concept video features, which jointly exploit context diversity over time and space for summarization purposes. Together with consistency between video and summary enforced in our framework, our model can be applied to both labeled and unlabeled data, making our method preferable to real-world applications. Extensive and complete experiments on two benchmarks demonstrate the effectiveness of our model both quantitatively and qualitatively, and confirms its superiority over the state-of-the-arts.
SlidesLive
Similar Papers
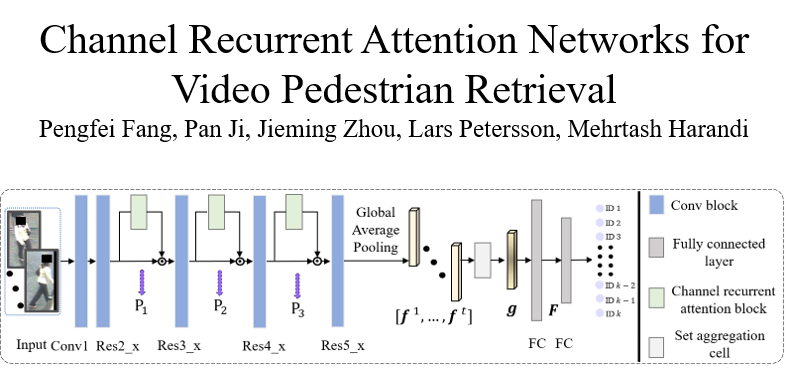
Channel Recurrent Attention Networks for Video Pedestrian Retrieval
Pengfei Fang (The Australian National University)*, Pan Ji (OPPO US Research Center), Jieming Zhou (The Australian National University), Lars Petersson (Data61/CSIRO), Mehrtash Harandi (Monash University)
Feedback Recurrent Autoencoder for Video Compression
Adam Golinski (University of Oxford)*, Reza Pourreza (Qualcomm), Yang Yang (Qualcomm Inc.), Guillaume Sautiere (Qualcomm AI Research), Taco S. Cohen (Qualcomm)
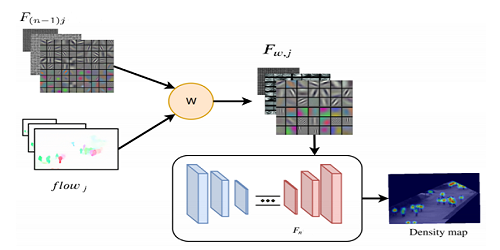
Video-Based Crowd Counting Using a Multi-Scale Optical Flow Pyramid Network
Mohammad Asiful Hossain (HUAWEI Technologies Co, LTD.)*, Kevin Cannons (Huawei Technologies Canada Co., Ltd ), Daesik Jang (Personal Research), Fabio Cuzzolin (Oxford Brookes University), Zhan Xu (Huawei Canada)