Data-Efficient Ranking Distillation for Image Retrieval
Zakaria Laskar (Aalto University)*, Juho Kannala (Aalto University, Finland)
Keywords: 3D Computer Vision; Recognition: Feature Detection, Indexing, Matching, and Shape Representation
Abstract:
Recent advances in deep learning has lead to rapid developments in the field of image retrieval. However, the best performing architectures incur significant computational cost. The paper addresses this issue using knowledge distillation for metric learning problems. Unlike previous approaches, our proposed method jointly addresses the following constraints: i) limited queries to teacher model, ii) black box teacher model with access to the final output representation, and iii) small fraction of original training data without any ground-truth labels. In addition, the distillation method does not require the student and teacher to have same dimensionality. The key idea is to augment the original training set with additional samples by performing linear interpolation in the final output representation space. In low training sample settings, our approach outperforms the fully supervised baseline approach on ROxford5k and RParis6k with the least possible teacher supervision.
SlidesLive
Similar Papers
Compensating for the Lack of Extra Training Data by Learning Extra Representation
Hyeonseong Jeon (Sungkyunkwan University)*, Siho Han (Sungkyunkwan University), Sangwon Lee (SKKU), Simon S. Woo (SKKU)
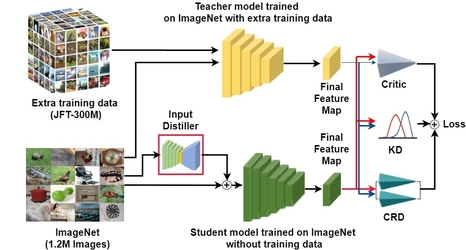
TinyGAN: Distilling BigGAN for Conditional Image Generation
Ting-Yun Chang (National Taiwan University)*, Chi-Jen Lu (Academia Sinica)
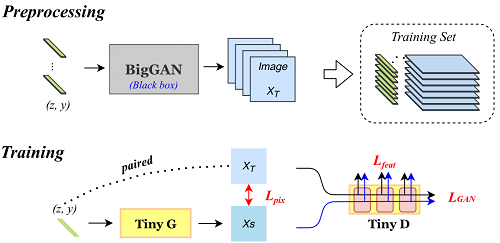
Learn more, forget less: Cues from human brain
Arijit Patra (University of Oxford), Tapabrata Chakraborti (University of Oxford)*