TinyGAN: Distilling BigGAN for Conditional Image Generation
Ting-Yun Chang (National Taiwan University)*, Chi-Jen Lu (Academia Sinica)
Keywords: Generative models for computer vision
Abstract:
Generative Adversarial Networks (GANs) have become a powerful approach for generative image modeling. However, GANs are notorious for their training instability, especially on large-scale, complex datasets. While the recent work of BigGAN has significantly improved the quality of image generation on ImageNet, it requires a huge model, making it hard to deploy on resource-constrained devices. To reduce the model size, we propose a black-box knowledge distillation framework for compressing GANs, which highlights a stable and efficient training process. Given BigGAN as the teacher network, we manage to train a much smaller student network to mimic its functionality, achieving competitive performance on Inception and FID scores with the generator having 16 times fewer parameters.
SlidesLive
Similar Papers
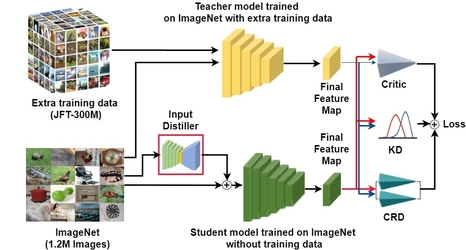
Compensating for the Lack of Extra Training Data by Learning Extra Representation
Hyeonseong Jeon (Sungkyunkwan University)*, Siho Han (Sungkyunkwan University), Sangwon Lee (SKKU), Simon S. Woo (SKKU)
Data-Efficient Ranking Distillation for Image Retrieval
Zakaria Laskar (Aalto University)*, Juho Kannala (Aalto University, Finland)

Active Learning for Video Description With Cluster-Regularized Ensemble Ranking
David M. Chan (University of California, Berkeley)*, Sudheendra Vijayanarasimhan (Google research), David A. Ross (Google), John F. Canny (UC Berkeley)