3D Object Detection from Consecutive Monocular Images
Chia-Chun Cheng (National Tsing Hua University)*, Shang-Hong Lai (Microsoft)
Keywords: 3D Computer Vision; Motion and Tracking; RGBD and Depth Image Processing; Robot Vision
Abstract:
Detecting objects in 3D space plays an important role in scene understanding, such as urban autonomous driving and mobile robot navigation. Many image-based methods are recently proposed due to the high cost of LiDAR. However, monocular images are lack of depth information and difficult to detect objects with occlusion. In this paper, we propose to integrate 2D/3D object detection and 3D motion estimation for consecutive monocular images to overcome these problems. Additionally, we estimate the relative motion of the object between frames to reconstruct the scene in the previous timestamp. Then, we can recover depth cues from multi-view geometric constraints. To learn motion estimation from unlabeled data, we propose an unsupervised motion loss which learns 3D motion estimation from consecutive images. Our experiments on KITTI dataset show that the proposed method outperforms the state-of-the-art methods for 3D Pedestrian and Cyclist detection and achieves competitive results for 3D Car detection.
SlidesLive
Similar Papers
Semantic Synthesis of Pedestrian Locomotion
Maria Priisalu (Lund University)*, Ciprian Paduraru (IMAR), Aleksis Pirinen (Lund University), Cristian Sminchisescu (Lund University)

A Two-Stage Minimum Cost Multicut Approach to Self-Supervised Multiple Person Tracking
Kalun Ho (Fraunhofer ITWM)*, Amirhossein Kardoost (University of Mannheim), Franz-Josef Pfreundt (Fraunhofer ITWM), Janis Keuper (hs-offenburg), Margret Keuper (University of Mannheim)
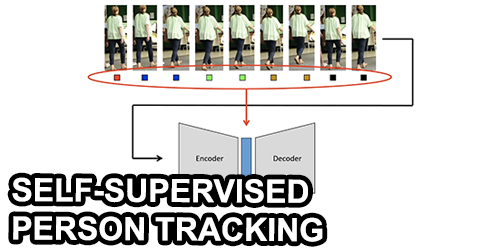
Efficient Large-Scale Semantic Visual Localization in 2D Maps
Tomas Vojir (CMP CTU)*, Ignas Budvytis (Department of Engineering, University of Cambridge), Roberto Cipolla (University of Cambridge)