V2A - Vision to Action: Learning robotic arm actions based on vision and language
Michal Nazarczuk (Imperial College London)*, Krystian Mikolajczyk (Imperial College London)
Keywords: Robot Vision
Abstract:
In this work, we present a new AI task - Vision to Action (V2A) - where an agent (robotic arm) is asked to perform a high-level task with objects (e.g. stacking) present in a scene. The agent has to suggest a plan consisting of primitive actions (e.g. simple movement, grasping) in order to successfully complete the given task. Instructions are formulated in a way that forces the agent to perform visual reasoning over the presented scene before inferring the actions. We extend the recently introduced dataset SHOP-VRB with task instructions for each scene as well as an engine capable of assessing whether the sequence of primitives leads to a successful task completion. We also propose a novel approach based on multimodal attention for this task and demonstrate its performance on the new dataset.
SlidesLive
Similar Papers
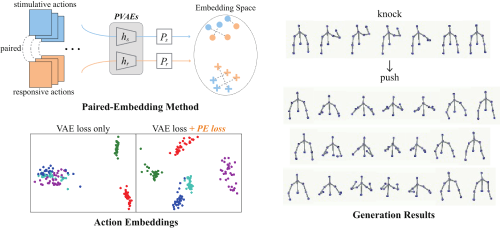
Learning End-to-End Action Interaction by Paired-Embedding Data Augmentation
Ziyang Song (Institute of Artificial Intelligence and Robotics, Xi'an Jiaotong University.)*, Zejian Yuan (Xi‘an Jiaotong University), Chong Zhang (Tencent Robotics X), Wanchao Chi (Tencent Robotics X), Yonggen Ling (Tencent), Shenghao Zhang (Tencent)
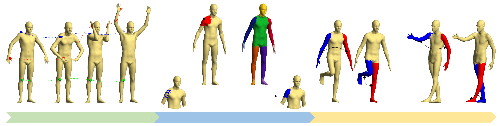
Novel-View Human Action Synthesis
Mohamed Ilyes Lakhal (Queen Mary University of London)*, Davide Boscaini (Fondazione Bruno Kessler), Fabio Poiesi (Fondazione Bruno Kessler), Oswald Lanz (Fondazione Bruno Kessler, Italy), Andrea Cavallaro (Queen Mary University of London, UK)
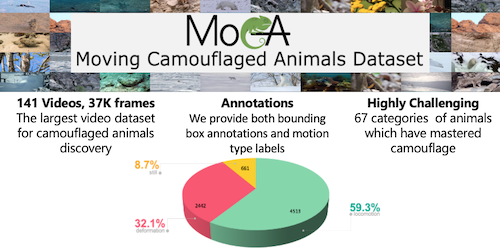
Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
Hala Lamdouar (University of Oxford)*, Charig Yang (University of Oxford), Weidi Xie (University of Oxford), Andrew Zisserman (University of Oxford)