Spatial Temporal Attention Graph Convolutional Networks with Mechanics-Stream for Skeleton-based Action Recognition
Katsutoshi Shiraki (Chubu University)*, Tsubasa Hirakawa (Chubu University), Takayoshi Yamashita (Chubu University), Hironobu Fujiyoshi (Chubu University)
Keywords: Face, Pose, Action, and Gesture
Abstract:
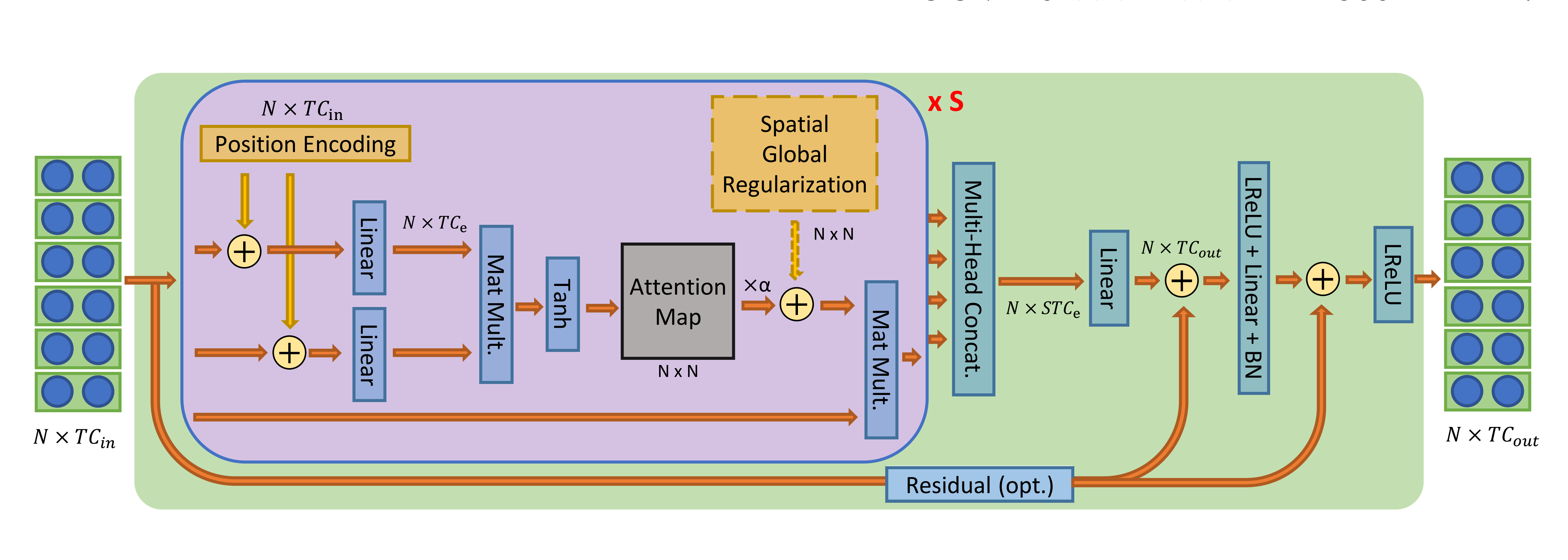
The static relationship between joints and the dynamic importance of joints leads to high accuracy in skeletal action recognition. Nevertheless, existing methods define the graph structure beforehand by skeletal patterns, so they cannot capture features considering the relationship between joints specific to actions. Moreover, the importance of joints is expected to be different for each action. We propose spatial-temporal attention graph convolutional networks (STA-GCN). It acquires an attention edge that represents a static relationship between joints for each action and an attention node that represents the dynamic importance of joints for each time. STA-GCN is the first method to consider joint importance and relationship at the same time. The proposed method consists of multiple networks, that reflect the difference of spatial (coordinates) and temporal (velocity and acceleration) characteristics as mechanics-stream. We aggregate these network predictions as final result. We show the potential that the attention edge and node can be easily applied to existing methods and improve the performance. Experimental results with NTU-RGB+D and NTU-RGB+D120 demonstrate that it is possible to obtain a attention edge and node specific to the action that can explain behavior and achieves state-of-the-art performances.
SlidesLive
Similar Papers
Decoupled Spatial-Temporal Attention Network for Skeleton-Based Action-Gesture Recognition
Lei Shi (Institute of Automation_�Chinese Academy of Sciences )*, Yifan Zhang (Institute of Automation, Chinese Academy of Sciences), Jian Cheng ("Chinese Academy of Sciences, China"), Hanqing Lu (NLPR, Institute of Automation, CAS)
Learning Global Pose Features in Graph Convolutional Networks for 3D Human Pose Estimation
Kenkun Liu ( University of Illinois at Chicago), Zhiming Zou (University of Illinois at Chicago), Wei Tang (University of Illinois at Chicago)*
RealSmileNet: A Deep End-To-End Network for Spontaneous and Posed Smile Recognition
Yan Yang (Australian National University)*, Md Zakir Hossain (The Australian National University ), Tom Gedeon (The Australian National University), Shafin Rahman (North South University)
