Jointly Discriminating and Frequent Visual Representation Mining
Qiannan Wang (Xidian university), Ying Zhou (Xidian University), ZhaoYan Zhu (Xidian university), Xuefeng Liang (Xidian University)*, Yu Gu (School of Artificial Intelligence, Xi'dian University)
Keywords: Recognition: Feature Detection, Indexing, Matching, and Shape Representation
Abstract:
Discovering visual representation in an image category is a challenging issue, because the visual representation should not only be discriminating but also frequently appears in these images. Previous studies have proposed many solutions, but they all separately optimized the discrimination and frequency, which makes the solutions sub-optimal. To address this issue, we propose a method to discover the jointly discriminating and frequent visual representation, named as JDFR. To ensure discrimination, JDFR employs a classification task with cross-entropy loss. To achieve frequency, JDFR uses triplet loss to optimize within-class and between-class distance, then mines frequent visual representations in feature space. Moreover, we propose an attention module to locate the representative region in the image. Extensive experiments on four benchmark datasets (i.e. CIFAR10, CIFAR100-20, VOC2012-10 and Travel) show that the discovered visual representations have better discrimination and frequency than ones mined from five state-of-the-art methods with average improvements of 7.51% on accuracy and 1.88% on frequency.
SlidesLive
Similar Papers
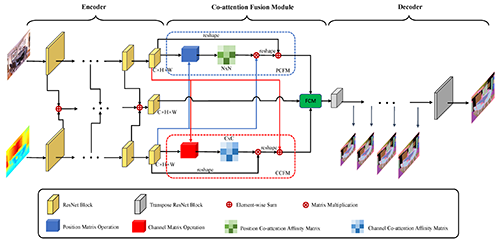
RGB-D Co-attention Network for Semantic Segmentation
Hao Zhou (Harbin Engineering University)*, Lu Qi (The Chinese University of Hong Kong), Zhaoliang Wan (Harbin Engineering University), Hai Huang (Harbin Engineering University), Xu Yang (Chinese Academy of Sciences)
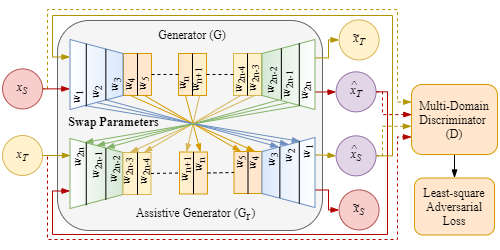
RF-GAN: A Light and Reconfigurable Network for Unpaired Image-to-Image Translation
Ali Koksal (Nanyang Technological University), Shijian Lu (Nanyang Technological University)*
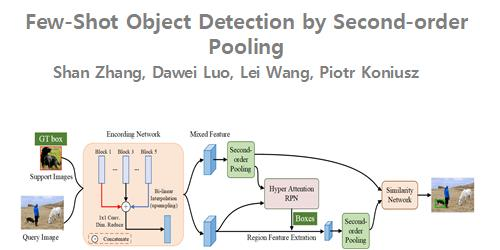
Few-Shot Object Detection by Second-order Pooling
Shan Zhang (ANU, Beijing Union University)*, Dawei Luo (Beijing Key Laboratory of Information Service Engineering, Beijing Union University ), Lei Wang ("University of Wollongong, Australia"), Piotr Koniusz (Data61/CSIRO, ANU)