MTNAS: Search Multi-Task Networks for Autonomous Driving
Hao Liu (Beijing Institute of Technology)*, Dong Li (Xilinx), JinZhang Peng (Xilinx), Qingjie Zhao (Beijing Institute of Technology), Lu Tian (Xilinx,Inc.), Yi Shan (Xilinx)
Keywords: Applications of Computer Vision, Vision for X
Abstract:
Multi-task learning (MTL) aims to learn shared representations from multiple tasks simultaneously, which has yielded outstanding performance in widespread applications of computer vision. However, existing multi-task approaches often demand manual design on network architectures, including shared backbone and individual branches. In this work, we propose MTNAS, a practical and principled neural architecture search algorithm for multi-task learning. We focus on searching for the overall optimized network architecture with task-specific branches and task-shared backbone. Specifically, the MTNAS pipeline consists of two searching stages: branch search and backbone search. For branch search, we separately optimize each branch structure for each target task. For backbone search, we first design a pre-searching procedure t1o pre-optimize the backbone structure on ImageNet. We observe that searching on such auxiliary large-scale data can not only help learn low-/mid-level features but also offer good initialization of backbone structure. After backbone pre-searching, we further optimize the backbone structure for learning task-shared knowledge under the overall multi-task guidance. We apply MTNAS to joint learning of object detection and semantic segmentation for autonomous driving. Extensive experimental results demonstrate that our searched multi-task model achieves superior performance for each task and consumes less computation complexity compared to prior hand-crafted MTL baselines. Code and searched models will be released at https://github.com/RalphLiu/MTNAS.
SlidesLive
Similar Papers
Modular Graph Attention Network for Complex Visual Relational Reasoning
Yihan Zheng (South China University of Technology), Zhiquan Wen (South China University of Technology), Mingkui Tan (South China University of Technology)*, Runhao Zeng (South China University of Technology), Qi Chen (South China University of Technology), Yaowei Wang (PengCheng Laboratory), Qi Wu (University of Adelaide)
Sequential View Synthesis with Transformer
Phong Nguyen-Ha (University of Oulu)*, Lam Huynh ( University of Oulu), Esa Rahtu (Tampere University), Janne Heikkila (University of Oulu, Finland)
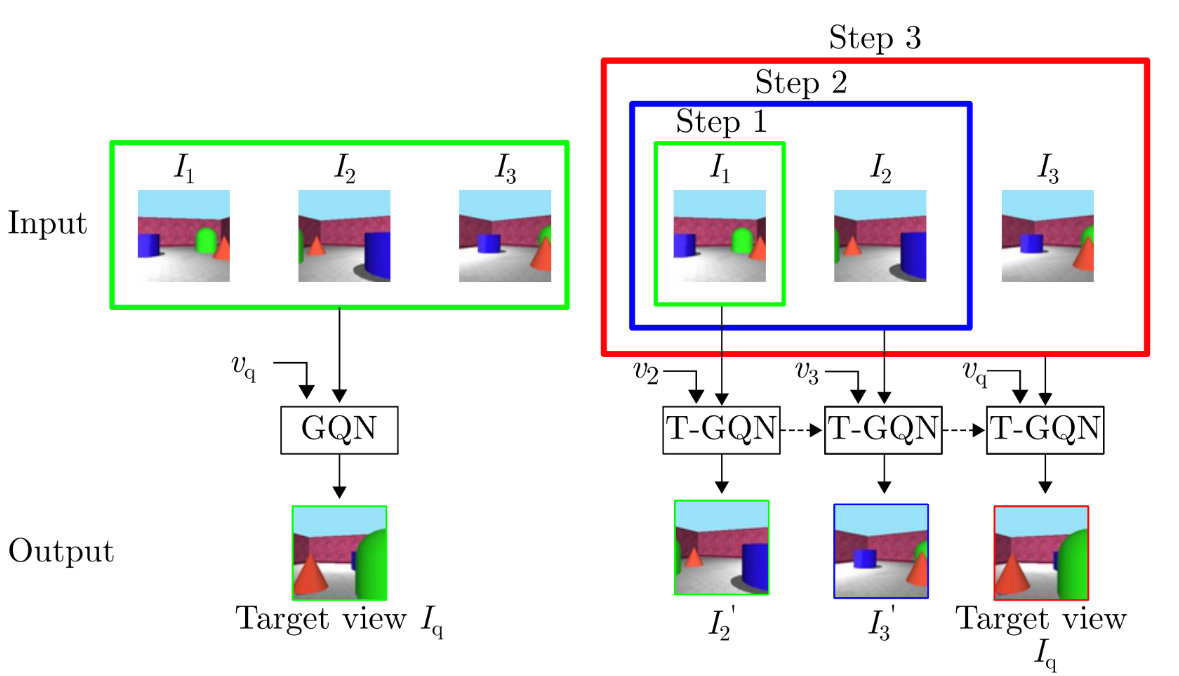
Second Order enhanced Multi-glimpse Attention in Visual Question Answering
Qiang Sun (Fudan University)*, Binghui Xie (Fudan University), Yanwei Fu (Fudan University)