Sequential View Synthesis with Transformer
Phong Nguyen-Ha (University of Oulu)*, Lam Huynh ( University of Oulu), Esa Rahtu (Tampere University), Janne Heikkila (University of Oulu, Finland)
Keywords: 3D Computer Vision
Abstract:
This paper addresses the problem of novel view synthesis by means of neural rendering, where we are interested in predicting the novel view at an arbitrary camera pose based on a given set of input imagesfrom other viewpoints. Using the known query pose and input poses, we create an ordered set of observations that leads to the target view. Thus, the problem of single novel view synthesis is reformulated as a sequential view prediction task. In this paper, the proposed Transformer-based Generative Query Network (T-GQN) extends the neural-rendering methods by adding two new concepts. First, we use multi-view attention learning between context images to obtain multiple implicit scene representations. Second, we introduce a sequential rendering decoder to predict an image sequence, including the target view, based on the learned representations. Finally, we evaluate our model on various challenging datasets and demonstrate that our model not only gives consistent predictions but also doesn’t require any retraining for fine-tuning.
SlidesLive
Similar Papers
Second Order enhanced Multi-glimpse Attention in Visual Question Answering
Qiang Sun (Fudan University)*, Binghui Xie (Fudan University), Yanwei Fu (Fudan University)
MTNAS: Search Multi-Task Networks for Autonomous Driving
Hao Liu (Beijing Institute of Technology)*, Dong Li (Xilinx), JinZhang Peng (Xilinx), Qingjie Zhao (Beijing Institute of Technology), Lu Tian (Xilinx,Inc.), Yi Shan (Xilinx)
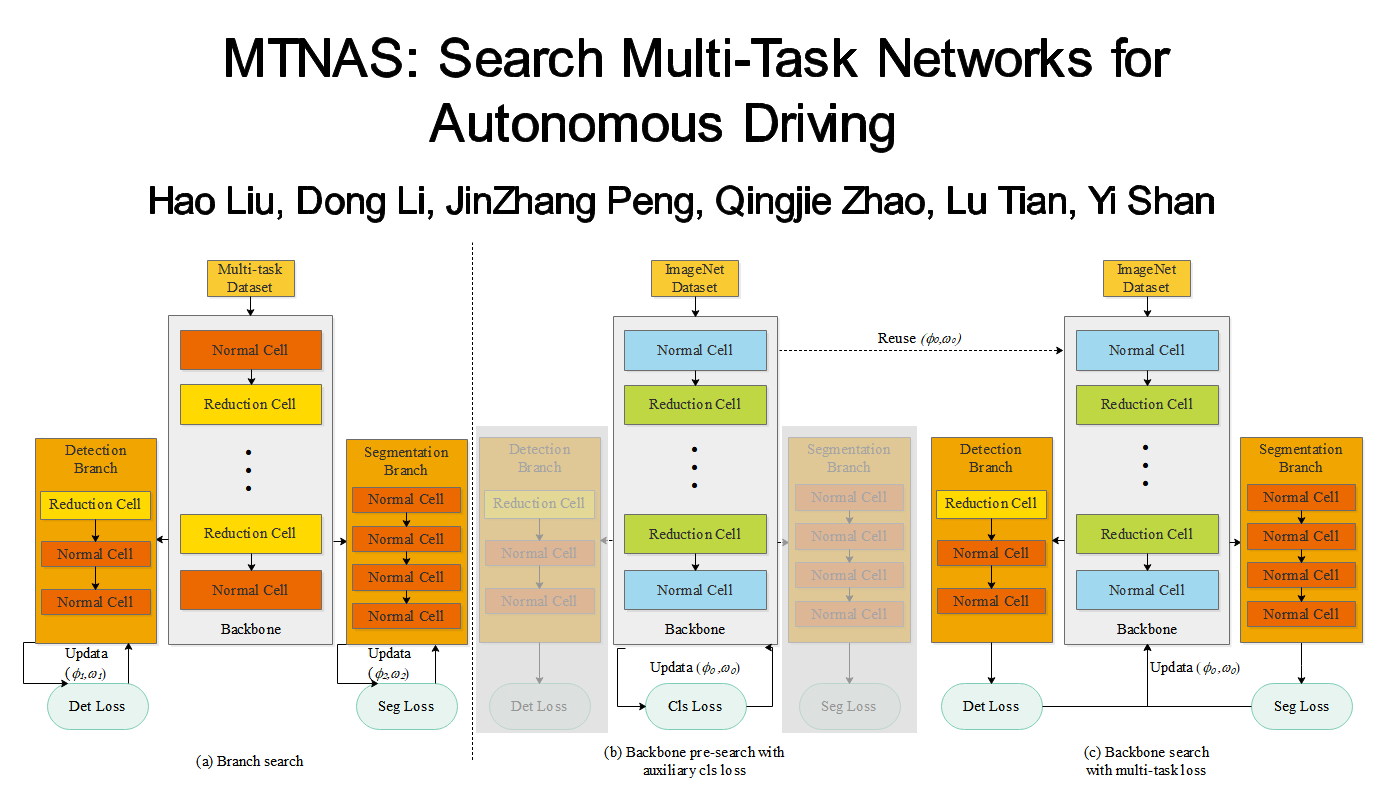
Goal-GAN: Multimodal Trajectory Prediction Based on Goal Position Estimation
Patrick Dendorfer (TUM)*, Aljosa Osep (TUM Munich), Laura Leal-Taixé (TUM)