Modular Graph Attention Network for Complex Visual Relational Reasoning
Yihan Zheng (South China University of Technology), Zhiquan Wen (South China University of Technology), Mingkui Tan (South China University of Technology)*, Runhao Zeng (South China University of Technology), Qi Chen (South China University of Technology), Yaowei Wang (PengCheng Laboratory), Qi Wu (University of Adelaide)
Keywords: Applications of Computer Vision, Vision for X
Abstract:
Visual Relational Reasoning is crucial for many vision-and-language based tasks, such as Visual Question Answering and Vision Language Navigation. In this paper, we consider reasoning on complex referring expression comprehension (c-REF) task that seeks to localise the target objects in an image guided by complex queries. Such queries often contain complex logic and thus impose two key challenges for reasoning: (i) It can be very difficult to comprehend the query since it often refers to multiple objects and describes complex relationships among them. (ii) It is non-trivial to reason among multiple objects guided by the query and localise the target correctly. To address these challenges, we propose a novel Modular Graph Attention Network (MGA-Net). Specifically, to comprehend the long queries, we devise a language attention network to decompose them into four types: basic attributes, absolute location, visual relationship and relative locations, which mimics the human language understanding mechanism. Moreover, to capture the complex logic in a query, we construct a relational graph to represent the visual objects and their relationships, and propose a multi-step reasoning method to progressively understand the complex logic. Extensive experiments on CLEVR-Ref+, GQA and CLEVR-CoGenT datasets demonstrate the superior reasoning performance of our MGA-Net.
SlidesLive
Similar Papers
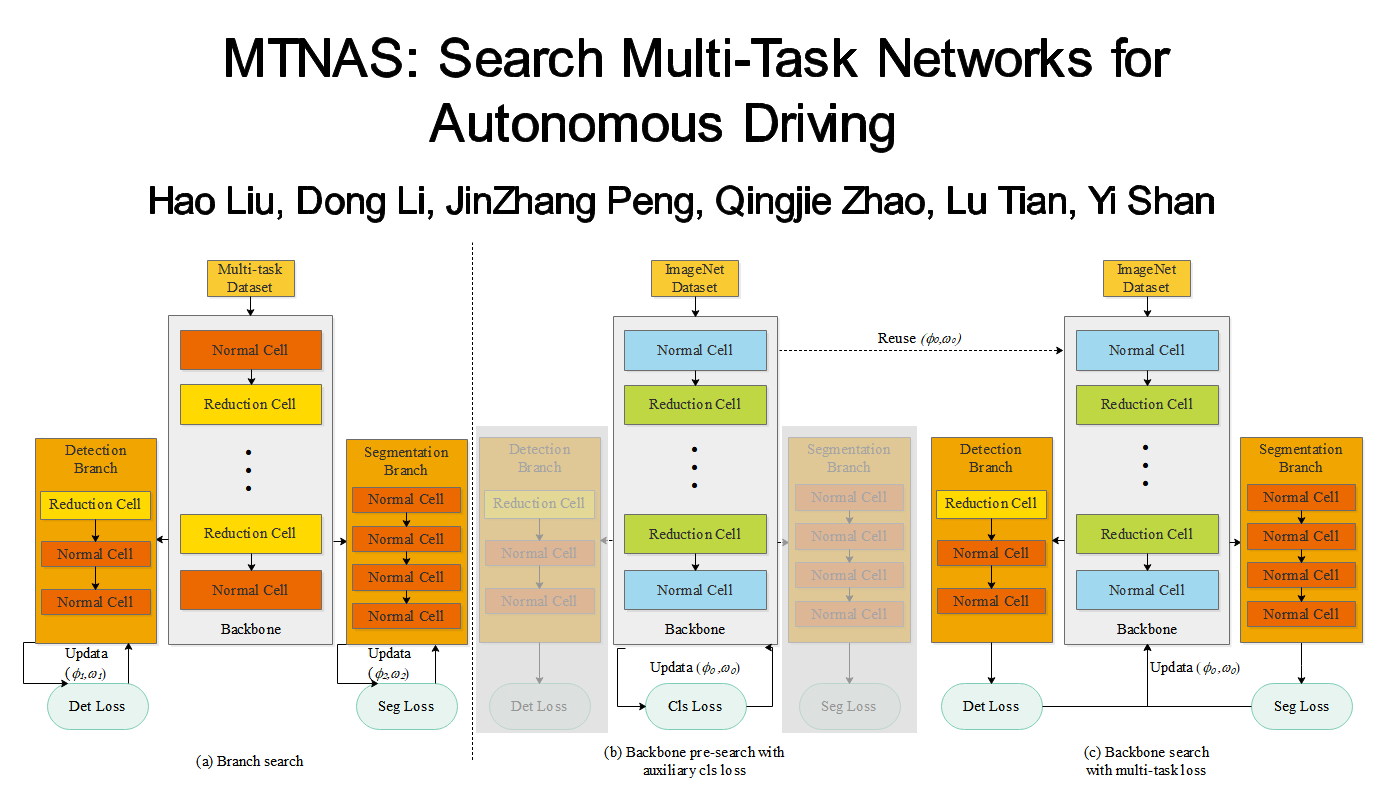
MTNAS: Search Multi-Task Networks for Autonomous Driving
Hao Liu (Beijing Institute of Technology)*, Dong Li (Xilinx), JinZhang Peng (Xilinx), Qingjie Zhao (Beijing Institute of Technology), Lu Tian (Xilinx,Inc.), Yi Shan (Xilinx)
CPTNet: Cascade Pose Transform Network for Single Image Talking Head Animation
Jiale Zhang (Huazhong University of Science and Technology), Ke Xian (Huazhong University of Science and Technology), Chengxin Liu (Huazhong University of Science and Technology)*, Yinpeng Chen (Huazhong University of Science and Technology), Zhiguo Cao (Huazhong Univ. of Sci.&Tech.), Weicai Zhong (Huawei CBG Consumer Cloud Service Big Data Platform Dept.)

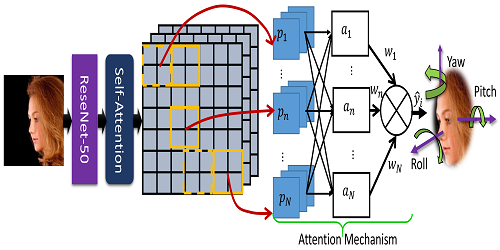
Rotation Axis Focused Attention Network (RAFA-Net) for Estimating Head Pose
Ardhendu Behera (Edge Hill University)*, Zachary Wharton (Edge Hill University), Pradeep Hewage (Edge Hill University), Swagat Kumar (Edge Hill University)