CPTNet: Cascade Pose Transform Network for Single Image Talking Head Animation
Jiale Zhang (Huazhong University of Science and Technology), Ke Xian (Huazhong University of Science and Technology), Chengxin Liu (Huazhong University of Science and Technology)*, Yinpeng Chen (Huazhong University of Science and Technology), Zhiguo Cao (Huazhong Univ. of Sci.&Tech.), Weicai Zhong (Huawei CBG Consumer Cloud Service Big Data Platform Dept.)
Keywords: Generative models for computer vision
Abstract:
We study the problem of talking head animation from a sin-gle image. Most of the existing methods focus on generating talking headsfor human. However, little attention has been paid to the creation of talk-ing head anime. In this paper, our goal is to synthesize vivid talking headsfrom a single anime image. To this end, we propose cascade pose trans-form network, termed CPTNet, that consists of a face pose transformnetwork and a head pose transform network. Specifically, we introducea mask generator to animate facial expression (e.g., close eyes and openmouth) and a grid generator for head movement animation, followed by afusion module to generate talking heads. In order to handle large motionand obtain more accurate results, we design a pose vector decomposi-tion and cascaded refinement strategy. In addition, we create an animetalking head dataset, that includes various anime characters and poses,to train our model. Extensive experiments on our dataset demonstratethat our model outperforms other methods, generating more accurateand vivid talking heads from a single anime image.
SlidesLive
Similar Papers
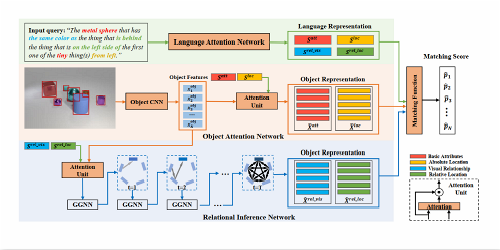
Rotation Axis Focused Attention Network (RAFA-Net) for Estimating Head Pose
Ardhendu Behera (Edge Hill University)*, Zachary Wharton (Edge Hill University), Pradeep Hewage (Edge Hill University), Swagat Kumar (Edge Hill University)
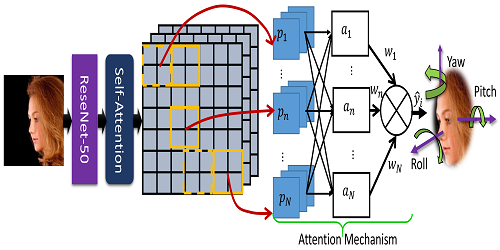
Domain-transferred Face Augmentation Network
Hao-Chiang Shao (Fu Jen Catholic University), Kang-Yu Liu (National Tsing Hua University), Chia-Wen Lin (National Tsing Hua University)*, Jiwen Lu (Tsinghua University)
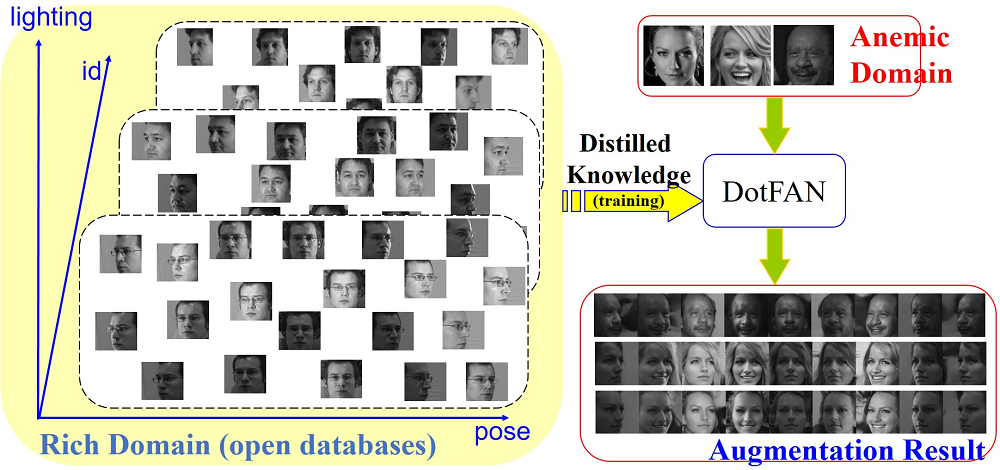
Modular Graph Attention Network for Complex Visual Relational Reasoning
Yihan Zheng (South China University of Technology), Zhiquan Wen (South China University of Technology), Mingkui Tan (South China University of Technology)*, Runhao Zeng (South China University of Technology), Qi Chen (South China University of Technology), Yaowei Wang (PengCheng Laboratory), Qi Wu (University of Adelaide)