Modeling Cross-Modal interaction in a Multi-detector, Multi-modal Tracking Framework
Yiqi Zhong (University of Southern California)*, Suya You (US Army Research Laboratory), Ulrich Neumann (USC)
Keywords: Motion and Tracking
Abstract:
Different modalities have their own advantages and disadvantages. In a tracking-by-detection framework, fusing data from multiple modalities would ideally improve tracking performance than using a single modality, but this is a challenge. This study builds upon previous research in this area. We propose a deep-learning based tracking-by-detection pipeline that uses multiple detectors and multiple sensors. For the input, we associate object proposals from 2D and 3D detectors. Through a cross-modal attention module, we optimize interaction between the 2D RGB and 3D point clouds features of each proposal. This helps to generate 2D features with suppressed irrelevant information for boosting performance. Through experiments on a published benchmark, we prove the value and ability of our design in introducing a multi-modal tracking solution to the current research on Multi-Object Tracking (MOT).
SlidesLive
Similar Papers
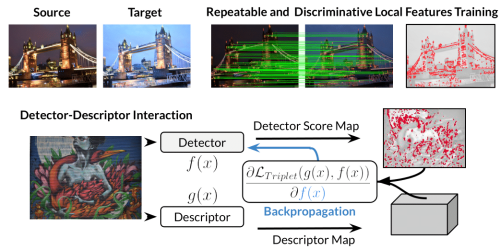
HDD-Net: Hybrid Detector Descriptor with Mutual Interactive Learning
Axel Barroso-Laguna (Imperial College London)*, Yannick Verdie (Huawei Noah's Ark Lab), Benjamin Busam (Technical University of Munich), Krystian Mikolajczyk (Imperial College London)
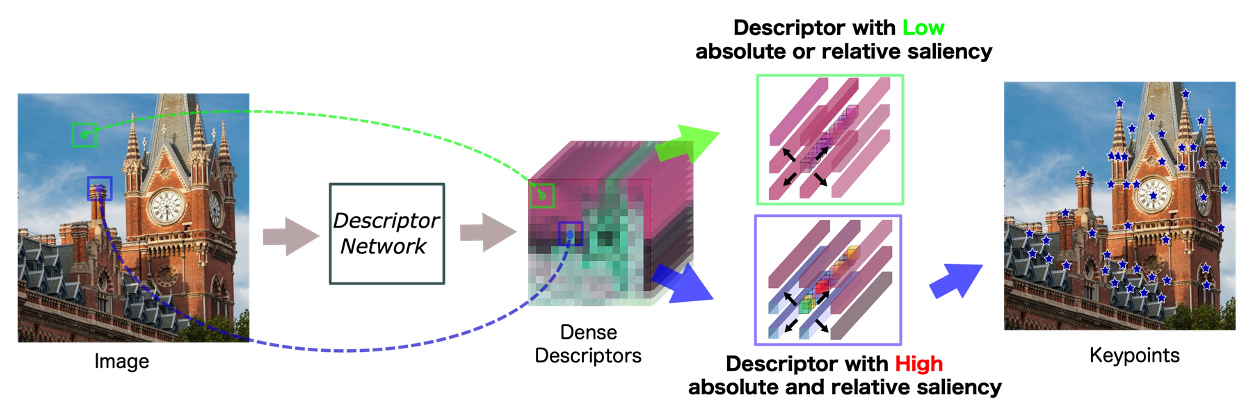
D2D: Keypoint Extraction with Describe to Detect Approach
Yurun Tian (Imperial College London)*, Vassileios Balntas (Scape Technologies), Tony Ng (Imperial College London), Axel Barroso-Laguna (Imperial College London), Yiannis Demiris (Imperial College London), Krystian Mikolajczyk (Imperial College London)
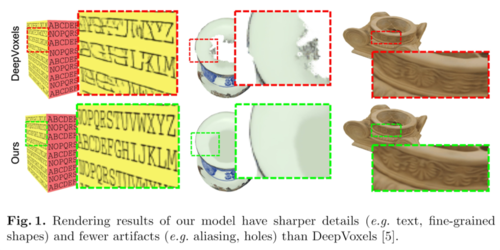
DeepVoxels++: Enhancing the Fidelity of Novel View Synthesis from 3D Voxel Embeddings
Tong He (UCLA)*, John Collomosse (Adobe Research), Hailin Jin (Adobe Research), Stefano Soatto (UCLA)