DeepVoxels++: Enhancing the Fidelity of Novel View Synthesis from 3D Voxel Embeddings
Tong He (UCLA)*, John Collomosse (Adobe Research), Hailin Jin (Adobe Research), Stefano Soatto (UCLA)
Keywords: 3D Computer Vision
Abstract:
We present a novel view synthesis method based upon latent voxel embeddings of an object, which encode both shape and appearance information and are learned without explicit 3D occupancy supervision. Our method uses an encoder-decoder architecture to learn such deep volumetric representations from a set of images taken at multiple viewpoints. Compared with DeepVoxels, our DeepVoxels++ applies a series of enhancements: a) a patch-based image feature extraction and neural rendering scheme that learns local shape and texture patterns, and enables neural rendering at high resolution; b) learned view-dependent feature transformation kernels to explicitly model perspective transformations induced by viewpoint changes; c) a recurrent-concurrent aggregation technique to alleviate single-view update bias of the voxel embeddings recurrent learning process. Combined with d) a simple yet effective implementation trick of frustum representation sufficient sampling, we achieve improved visual quality over the prior deep voxel-based methods (33% SSIM error reduction and 22% PSNR improvement) on 360-degree novel-view synthesis benchmarks.
SlidesLive
Similar Papers
Weakly-supervised Reconstruction of 3D Objects with Large Shape Variation from Single In-the-Wild Images
Shichen Sun (Sichuan University), Zhengbang Zhu (Sichuan University), Xiaowei Dai (Sichuan University), Qijun Zhao (Sichuan University)*, Jing Li (Sichuan University)
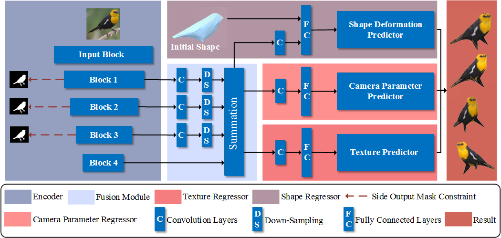
Dynamic Depth Fusion and Transformation for Monocular 3D Object Detection
Erli Ouyang (Fudan University)*, Li Zhang (University of Oxford), Mohan Chen (Fudan University), Anurag Arnab (University of Oxford), Yanwei Fu (Fudan University)
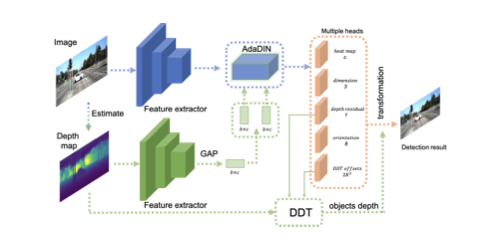
D2D: Keypoint Extraction with Describe to Detect Approach
Yurun Tian (Imperial College London)*, Vassileios Balntas (Scape Technologies), Tony Ng (Imperial College London), Axel Barroso-Laguna (Imperial College London), Yiannis Demiris (Imperial College London), Krystian Mikolajczyk (Imperial College London)