HDD-Net: Hybrid Detector Descriptor with Mutual Interactive Learning
Axel Barroso-Laguna (Imperial College London)*, Yannick Verdie (Huawei Noah's Ark Lab), Benjamin Busam (Technical University of Munich), Krystian Mikolajczyk (Imperial College London)
Keywords: 3D Computer Vision
Abstract:
Local feature extraction remains an active research area due to the advances in fields such as SLAM, 3D reconstructions, or AR applications. The success in these applications relies on the performance of the feature detector, descriptor, and its matching process. While the trend of detector-descriptor interaction of most methods is based on unifying the two into a single network, we propose an alternative approach that treats both components independently and focuses on their interaction during the learning process. We formulate the classical hard-mining triplet loss as a new detector optimisation term to improve keypoint positions based on the descriptor map. Moreover, we introduce a dense descriptor that uses a multi-scale approach within the architecture and a hybrid combination of hand-crafted and learnt features to obtain rotation and scale robustness by design. We evaluate our method extensively on several benchmarks and show improvements over the state of the art in terms of image matching and 3D reconstruction quality while keeping on par in camera localisation tasks.
SlidesLive
Similar Papers
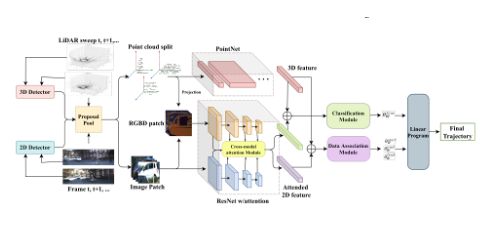
Modeling Cross-Modal interaction in a Multi-detector, Multi-modal Tracking Framework
Yiqi Zhong (University of Southern California)*, Suya You (US Army Research Laboratory), Ulrich Neumann (USC)
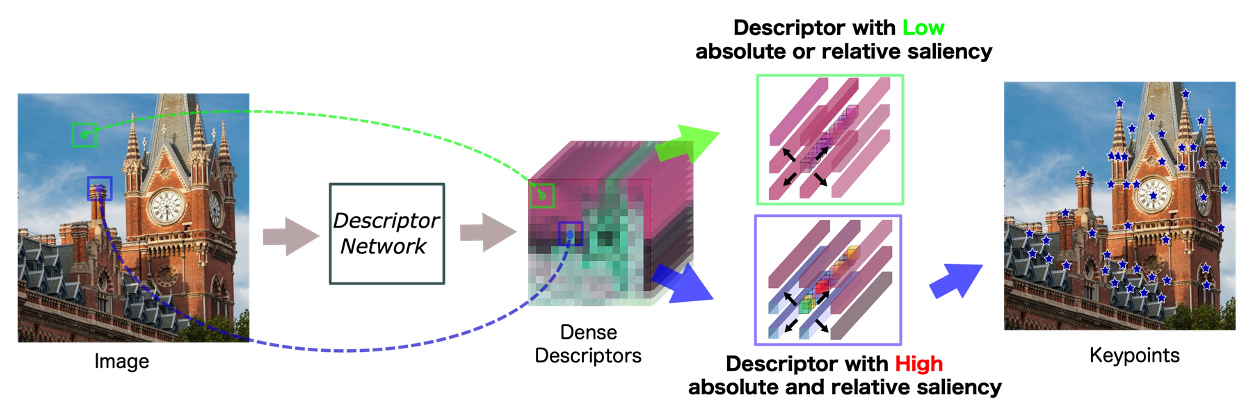
D2D: Keypoint Extraction with Describe to Detect Approach
Yurun Tian (Imperial College London)*, Vassileios Balntas (Scape Technologies), Tony Ng (Imperial College London), Axel Barroso-Laguna (Imperial College London), Yiannis Demiris (Imperial College London), Krystian Mikolajczyk (Imperial College London)
Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation
Jihun Yi (Seoul National University), Sungroh Yoon (Seoul National University)*