Rotation Equivariant Orientation Estimation for Omnidirectional Localization
Chao Zhang (Toshiba Europe Limited)*, Ignas Budvytis (Department of Engineering, University of Cambridge), Stephan Liwicki (Toshiba Europe Limited), Roberto Cipolla (University of Cambridge)
Keywords: Deep Learning for Computer Vision
Abstract:
Deep learning for 6-degree-of-freedom (6-DoF) camera pose estimation is highly efficient at test time and can achieve accurate results in challenging, weakly textured environments. Typically, however, success in deep learning relies on large amounts of training images spanning many orientations and positions of the environment making it impractical for medium size or large environments. In this work we present a direct 6-DoF camera pose estimation method which alleviates the need for orientation augmentation at train time while still supporting any SO(3) rotation at test time. This property is achieved by the following three step procedure. Firstly, omni-directional training images are rotated to a common orientation. Secondly, a fully rotation equivariant CNN encoder is applied and its output is used to obtain: (i) a rotation invariant prediction of the camera position and (ii) a rotation equivariant prediction of the probability distribution over camera orientations. Finally, for a test image of a novel orientation, the camera position is predicted robustly due to in-built rotation invariance, while the camera orientation is recovered from the relative shift of the peak in the probability distribution of camera orientations. We demonstrate our approach on synthetic and real-image datasets, where we significantly outperform classical CNN-based pose regression, (i) in terms of accuracy when a single training orientation is used, and (ii) in training efficiency when orientation augmentation is employed. To the best of our knowledge, our proposed rotation equivariant CNN for localization is the first direct pose estimation method able to predict orientation without explicit rotation augmentation at train time.
SlidesLive
Similar Papers
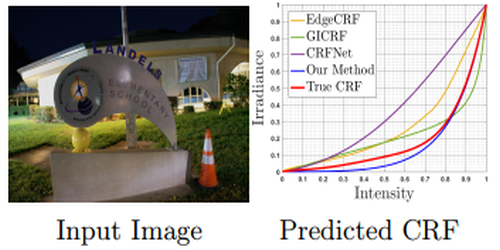
Single-Image Camera Response Function Using Prediction Consistency and Gradual Refinement
Aashish Sharma (National University of Singapore)*, Robby T. Tan (Yale-NUS College), Loong-Fah Cheong (NUS)
Learning Local Feature Descriptors for Multiple Object Tracking
Dmytro Borysenko (Samsung R&D Institute Ukraine), Dmytro Mykheievskyi (Samsung R&D Institute Ukraine), Viktor Porokhonskyy (Samsung Research&Development Institute Ukraine (SRK))*
Self-supervised Learning of Orc-Bert Augmentator for Recognizing Few-Shot Oracle Characters
Wenhui Han (Fudan University), Xinlin Ren (Fudan University), Hangyu Lin (Fudan University), Yanwei Fu (Fudan University)*, Xiangyang Xue (Fudan University)