Play Fair: Frame Contributions in Video Models
Will Price (University of Bristol)*, Dima Damen (University of Bristol)
Keywords: Video Analysis and Event Recognition
Abstract:
In this paper, we introduce an attribution method for explaining action recognition models. Such models fuse information from multiple frames within a video, through score aggregation or relational reasoning. We break down a model’s class score into the sum of contributions from each frame, fairly. Our method adapts an axiomatic solution to fair reward distribution in cooperative games, known as the Shapley value, for elements in a variable-length sequence, which we call the Element Shapley Value (ESV). Critically, we propose a tractable approximation of ESV that scales linearly with the number of frames in the sequence.We employ ESV to explain two action recognition models (TRN and TSN) on the fine-grained dataset Something-Something. We offer detailed analysis of supporting/distracting frames, and the relationships of ESVs to the frame’s position, class prediction, and sequence length. We compare ESV to naive baselines and two commonly used attribution methods: Grad-CAM and Integrated-Gradients.
SlidesLive
Similar Papers
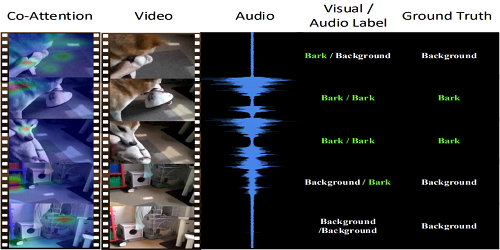
Audiovisual Transformer with Instance Attention for Audio-Visual Event Localization
Yan-Bo Lin (National Taiwan Unviersity)*, Yu-Chiang Frank Wang (National Taiwan University)
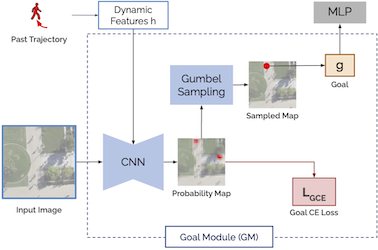
Goal-GAN: Multimodal Trajectory Prediction Based on Goal Position Estimation
Patrick Dendorfer (TUM)*, Aljosa Osep (TUM Munich), Laura Leal-Taixé (TUM)
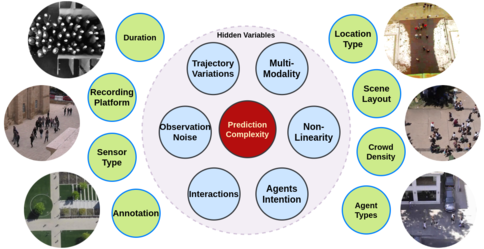
OpenTraj: Assessing Prediction Complexity in Human Trajectories Datasets
Javad Amirian (Inria, Rennes, France)*, Bingqing Zhang (UCL), Francisco Valente Castro (Cimat), Juan Jose Baldelomar (Cimat), Jean-Bernard Hayet (CIMAT), Julien Pettré (INRIA Rennes - Bretagne Atlantique)