Image Captioning through Image Transformer
Sen He (University of Exeter)*, Wentong Liao (Leibniz University Hannover), Hamed R. Tavakoli (Nokia Technologies), Michael Yang (University of Twente), Bodo Rosenhahn (Leibniz University Hannover), Nicolas Pugeault (University of Glasgow)
Keywords: Deep Learning for Computer Vision
Abstract:
Automatic captioning of images is a task that combines the challenges of image analysis and text generation. One important aspect of captioning is the notion of attention: how to decide what to describe and in which order. Inspired by the successes in text analysis and translation, previous works have proposed the transformer architecture for image captioning. However, the structure between the semantic units in images (usually the detected regions from object detection model) and sentences (each single word) is different. Limited work has been done to adapt to the transformer's internal architecture to images. In this work, we introduce the image transformer, which consists of a modified encoding transformer and an implicit decoding transformer, motivated by the relative spatial relationship between image regions. Our design widens the original transformer layer's inner architecture to adapt to the structure of images. With only regions feature as inputs, our model achieves new state-of-the-art performance on both MSCOCO offline and online testing benchmarks. The code is available at https://github.com/wtliao/ImageTransformer.
SlidesLive
Similar Papers
Show, Conceive and Tell: Image Captioning with Prospective Linguistic Information
Yiqing Huang (Tsinghua University), Jiansheng Chen (Tsinghua University)*

Query by Strings and Return Ranking Word Regions with Only One Look
Peng Zhao (Beijing Jiaotong University), Wenyuan Xue (Beijing Jiaotong University), Qingyong Li (Beijing Jiaotong University)*, Siqi Cai (Beijing Jiaotong University)
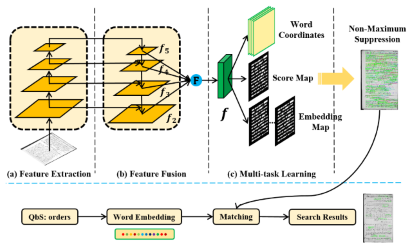
Rotation Axis Focused Attention Network (RAFA-Net) for Estimating Head Pose
Ardhendu Behera (Edge Hill University)*, Zachary Wharton (Edge Hill University), Pradeep Hewage (Edge Hill University), Swagat Kumar (Edge Hill University)