Adaptive Spotting: Deep Reinforcement Object Search in 3D Point Clouds
Onkar Krishna (NTT Corporation, Japan)*, Go Irie (NTT Corporation), Xiaomeng Wu (NTT Corporation), Takahito Kawanishi (NTT Corporation), Kunio Kashino (NTT Communication Science Laboratories)
Keywords: Recognition: Feature Detection, Indexing, Matching, and Shape Representation
Abstract:
In this paper, we study the task of searching for a query object of unknown position and pose in a scene, both given in the form of 3D point cloud data. A straightforward approach that exhaustively scans the scene is often prohibitive due to computational inefficiencies. High-quality feature representation also needs to be learned to achieve accurate recognition and localization. Aiming to address these two fundamental problems in a unified framework, we propose Adaptive Spotting, a deep reinforcement learning approach that jointly learns both the features and the efficient search path. Our network is designed to directly take raw point cloud data of the query object and the search bounding box and to sequentially determine the next pose to be searched. This network is successfully trained in an end-to-end manner by integrating a contrastive loss and a reinforcement localization reward. Evaluations on ModelNet40 and Stanford 2D-3D-S datasets demonstrate the superiority of the proposed approach over several state-of-the-art baselines.
SlidesLive
Similar Papers
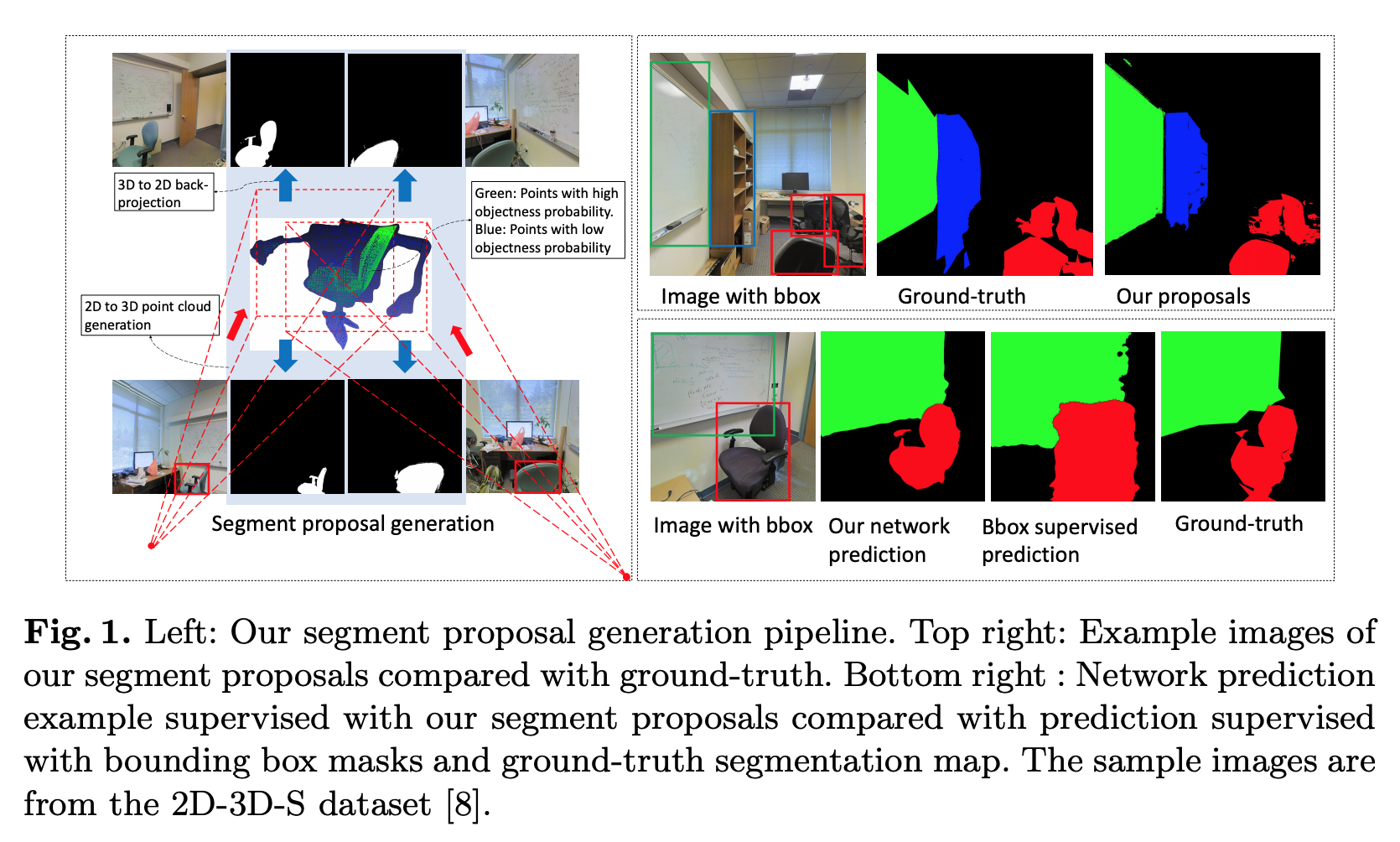
3D Guided Weakly Supervised Semantic Segmentation
Weixuan Sun (Australian National University, Data61 )*, Jing Zhang (Australian National University), Nick Barnes (ANU)
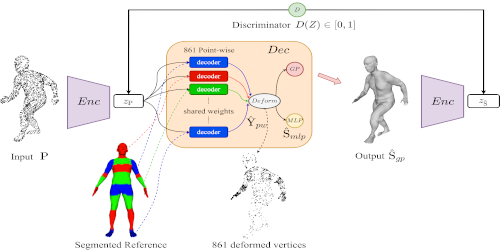
Reconstructing Human Body Mesh from Point Clouds by Adversarial GP Network
Boyao Zhou (Inria)*, Jean-Sebastien Franco (INRIA), Federica Bogo (Microsoft), Bugra Tekin (Microsoft), Edmond Boyer (Inria)
SpotPatch: Parameter-Efficient Transfer Learning for Mobile Object Detection
Keren Ye (University of Pittsburgh)*, Adriana Kovashka (University of Pittsburgh), Mark Sandler (Google), Menglong Zhu (UPenn), Andrew Howard (Google), Marco Fornoni (Google)