Watch, read and lookup: learning to spot signs from multiple supervisors
Liliane Momeni (University of Oxford), Gul Varol (University of Oxford)*, Samuel Albanie (University of Oxford), Triantafyllos Afouras (University of Oxford), Andrew Zisserman (University of Oxford)
Keywords: Applications of Computer Vision, Vision for X
Abstract:
The focus of this work is sign spotting--given a video of an isolated sign, our task is to identify whether and where it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) watching existing sparsely labelled footage; (2) reading associated subtitles (readily available translations of the signed content) which provide additional weak-supervision; (3) looking up words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page
SlidesLive
Similar Papers
Understanding Motion in Sign Language: A New Structured Translation Dataset
Jefferson Rodriguez (UIS), Juan Chacon (UIS), Edgar Rangel (UIS), Luis Guayacan (UIS), Claudia Hernandez (UIS), Luisa Hernandez (UIS), Fabio Martinez (UIS )*

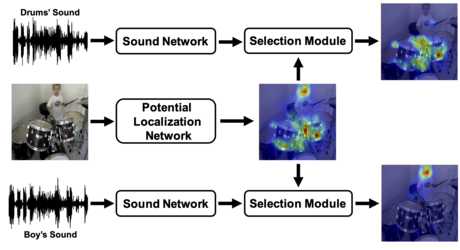
Do We Need Sound for Sound Source Localization?
Takashi Oya (Waseda University)*, Shohei Iwase (Waseda University ), Ryota Natsume (Waseda University), Takahiro Itazuri (Waseda University), Shugo Yamaguchi (Waseda University), Shigeo Morishima (Waseda Research Institute for Science and Engineering)
Unpaired Multimodal Facial Expression Recognition
Bin Xia (University of Science and Technology of China), Shangfei Wang (University of Science and Technology of China)*
