Understanding Motion in Sign Language: A New Structured Translation Dataset
Jefferson Rodriguez (UIS), Juan Chacon (UIS), Edgar Rangel (UIS), Luis Guayacan (UIS), Claudia Hernandez (UIS), Luisa Hernandez (UIS), Fabio Martinez (UIS )*
Keywords: Datasets and Performance Analysis; Face, Pose, Action, and Gesture
Abstract:
Sign languages are the main mechanism of communication and interaction in the Deaf community. These languages are highly variable in communication with divergences between gloss representation, sign configuration, and multiple variants, among others, due to cultural and regional aspects. Current methods for automatic and continuous sign translation include robust and deep learning models that encode the visual signs representation. Despite the significant progress, the convergence of such models requires huge amounts of data to exploit sign representation, resulting in very complex models. This fact is associated to the highest variability but also to the shortage exploration of many language components that support communication. For instance, gesture motion and grammatical structure are fundamental components in communication, which can deal with visual and geometrical sign misinterpretations during video analysis. This work introduces a new Colombian sign language translation dataset (CoL-SLTD), that focuses on motion and structural information, and could be a significant resource to determine the contribution of several language components. Additionally, an encoder-decoder deep strategy is herein introduced to support automatic translation, including attention modules that capture short, long, and structural kinematic dependencies and their respective relationships with sign recognition. The evaluation in CoL-SLTD proves the relevance of the motion representation, allowing compact deep architectures to represent the translation. Also, the proposed strategy shows promising results in translation, achieving Bleu-4 scores of 35.81 and 4.65 in signer independent and unseen sentences tasks.
SlidesLive
Similar Papers
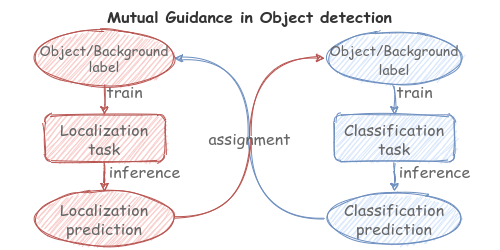
Watch, read and lookup: learning to spot signs from multiple supervisors
Liliane Momeni (University of Oxford), Gul Varol (University of Oxford)*, Samuel Albanie (University of Oxford), Triantafyllos Afouras (University of Oxford), Andrew Zisserman (University of Oxford)
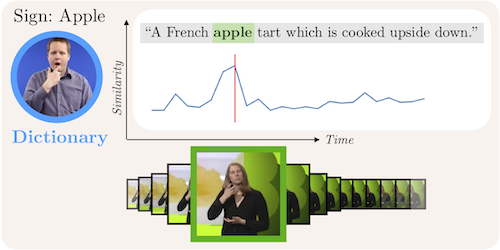
Do We Need Sound for Sound Source Localization?
Takashi Oya (Waseda University)*, Shohei Iwase (Waseda University ), Ryota Natsume (Waseda University), Takahiro Itazuri (Waseda University), Shugo Yamaguchi (Waseda University), Shigeo Morishima (Waseda Research Institute for Science and Engineering)
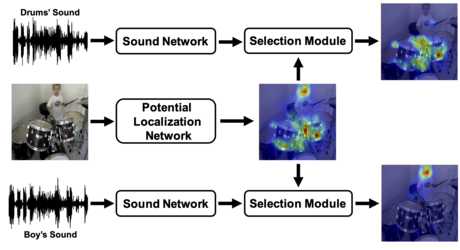
Localize to Classify and Classify to Localize: Mutual Guidance in Object Detection
Heng Zhang (Univ Rennes 1)*, Elisa Fromont (Université Rennes 1, IRISA/INRIA rba), Sébastien Lefèvre (Université de Bretagne Sud / IRISA), Bruno Avignon (Atermes)