Discovering Multi-Label Actor-Action Association in a Weakly Supervised Setting
Sovan Biswas (University of Bonn)*, Juergen Gall (University of Bonn)
Keywords: Video Analysis and Event Recognition
Abstract:
Since collecting and annotating data for spatio-temporal action detection is very expensive, there is a need to learn approaches with less supervision. Weakly supervised approaches do not require any bounding box annotations and can be trained only from labels that indicate whether an action occurs in a video clip. Current approaches, however, cannot handle the case when there are multiple persons in a video that perform multiple actions at the same time. In this work, we address this very challenging task for the first time. We propose a baseline based on multi-instance and multi-label learning. Furthermore, we propose a novel approach that uses sets of actions as representation instead of modeling individual action classes. Since computing the probabilities for the full power set becomes intractable as the number of action classes increases, we assign an action set to each detected person under the constraint that the assignment is consistent with the annotation of the video clip. We evaluate the proposed approach on the challenging AVA dataset where the proposed approach outperforms the MIML baseline and is competitive to fully supervised approaches.
SlidesLive
Similar Papers
Semi-supervised Facial Action Unit Intensity Estimation with Contrastive Learning
Enrique Sanchez (Samsung AI Centre)*, Adrian Bulat (Samsung AI Center, Cambridge), Anestis Zaganidis (Samsung), Georgios Tzimiropoulos (Queen Mary University of London)
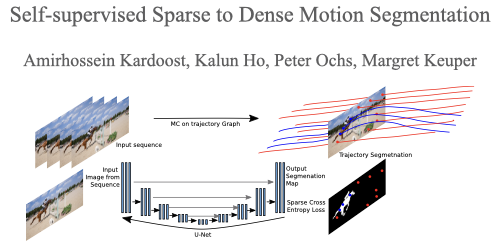
Self-supervised Sparse to Dense Motion Segmentation
Amirhossein Kardoost (University of Mannheim)*, Kalun Ho (Fraunhofer ITWM), Peter Ochs (Saarland University), Margret Keuper (University of Mannheim)
Self-supervised Learning of Orc-Bert Augmentator for Recognizing Few-Shot Oracle Characters
Wenhui Han (Fudan University), Xinlin Ren (Fudan University), Hangyu Lin (Fudan University), Yanwei Fu (Fudan University)*, Xiangyang Xue (Fudan University)